A Practical Guide to Azure AI + Bing Grounding in Python: Prompt Tuning, Cost Control, and Redis Caching
Guide to implement Azure AI agents into your Python app, selecting the right AI model for your use case, finetuning prompts, and optimizing with Redis. Includes a full cost analysis section with practical cost mitigation strategies. Live demo: zhf.danielstanecki.com
Table of Contents
- Project & Cost Overview
- About Grounding with Bing
- Set Up Azure AI + Bing
- Finetuning AI Prompts
- GPT-4 Engine Comparison
- Cost Analysis
- Cost Optimization Strategies (Rate Limiting, Redis Caching, CAPTCHA)
Project & Cost Overview
This post is intended for full stack engineers who are interested in leveraging Azure OpenAI with live web data using Bing Grounding, plus managing costs, caching with Redis, and prompt tuning. I’m using a Python Flask application hosted on a multi-node Kubernetes cluster.
GitHub repo: https://github.com/dstanecki/zillow-housing-forecast
Prerequisites:
- Existing Python app
- Azure account
This setup includes two main components that incur per-use costs:
| Component | Pricing | Notes |
|---|---|---|
| Azure AI Agent | ~$0.60–$10 per 1M tokens | Depends on engine (GPT-4.1-nano, mini, full). See full breakdown below. |
| Grounding with Bing | $35 per 1,000 requests | Flat fee, charged on top of AI agent usage. |
⚠️ If your app is public-facing, you must implement protections (e.g., rate limits, CAPTCHA) to avoid surprise costs, which I cover below.
About Grounding with Bing
Grounding with Bing addresses the major limitation seen with OpenAI’s (ChatGPT) API: not being able to browse the internet. To be clear, the ChatGPT app can, but it’s just the API that cannot. The API on its own has a knowledge cutoff of roughly 1 year ago, and is not up to date on current topics.
Azure AI agents allow you to use the ChatGPT models as an API and connect them to Bing for up-to-date knowledge.
How to Set Up Azure AI + Grounding with Bing
The setup is a bit confusing because you need to create the AI agent in the Azure AI Foundry portal, and then in the separate, normal Azure portal you need to create the “Grounding” resource (under the “Bing Resource” section https://learn.microsoft.com/en-us/azure/ai-foundry/agents/how-to/tools/bing-grounding).
Step 1: Create a Foundry account + project
Navigate to https://ai.azure.com and create an account. On the Overview page, select “Create new” > Azure AI Foundry resource and follow the prompts to create a project. Not all regions are compatible with AI agents!! I’m using US East 2.
Step 2: Create a Model deployment
Navigate to “Models + endpoints” in the sidebar and Deploy model. Here you have the option to choose the Deployment type (Global Standard, Data Zone Standard, etc.). That’s explained in detail here. Global Standard is pay-as-you-go and has the lowest price per-token so I’m going with that. My app is a live demo with low overall traffic so I don’t need to provision throughput in advance.
The default tokens per minute rate limit is 50K (the max). This is where you should calculate how much usage your app will see and set an appropriate limit. In the Python API call, you can pass an argument specifying a token limit. Depending on the engine you plan to use (o4-nano, o4-mini, GPT-4o, etc.), this number will vary, but for short paragraph responses in GPT-4o, 300 tokens is a generous allocation. If I have 2 users each triggering a request 6x/min and consuming 300 tokens per request, that’s 4,000 tokens per minute and I reckon that’s enough for my use case. More on this later.
Step 3: Open in Playground
Select Open in Playground:
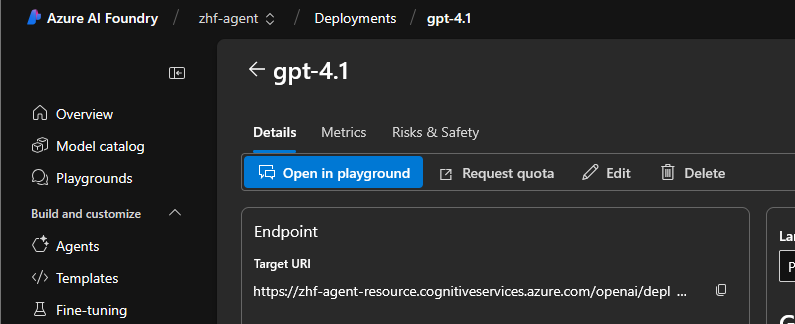
This will also generate an agent automatically.
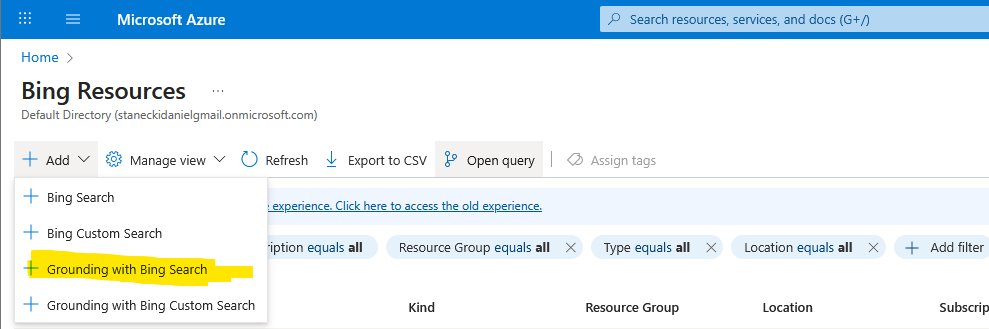
Step 4: Create Grounding with Bing resource
Navigate to the regular portal.azure.com > Bing Resources and add a Grounding with Bing Search:
Step 5: Create the Knowledge Connection
Back in ai.azure.com, navigate to Agents in the left sidebar and add a Knowledge connection:
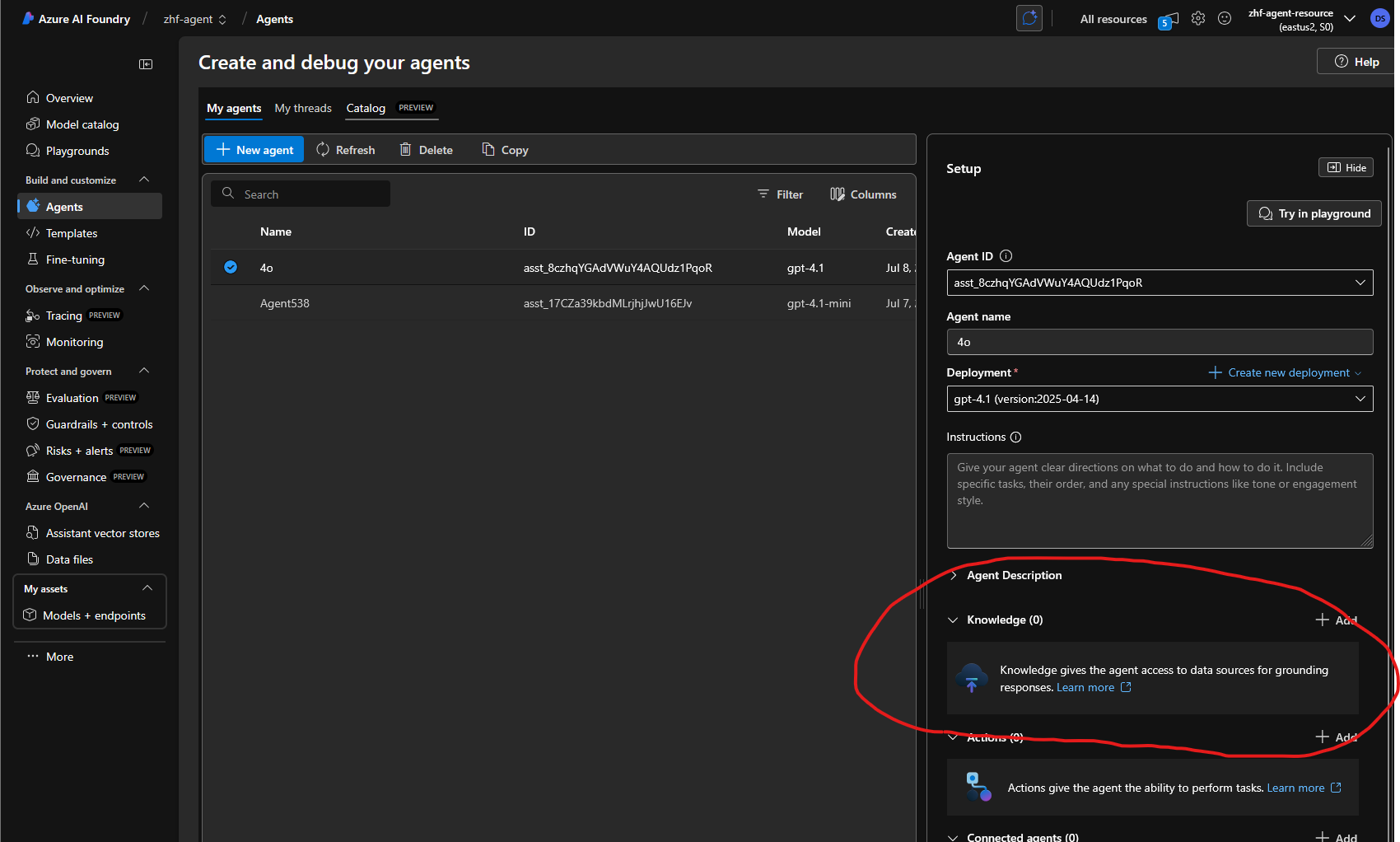
Then select your newly created Grounding with Bing resource.
How to Finetune AI Prompts
Knowing how to optimally enter AI prompts is a lot more important than most people realize. Especially when your app is hinging on the AI’s ability to scrape the web for up-to-date and comprehensive information. Check out my test in the GPT-4.1-nano playground. At first I was only pulling the ZIP code and forecast % to use in my prompt, which resulted in a generic and inaccurate response:
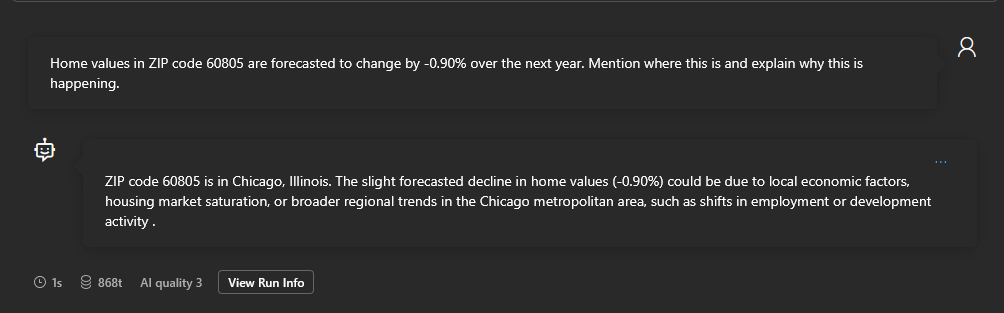 |
|---|
| GENERIC PROMPT |
60805 is not even in Chicago and the rest of the answer is egregiously bland. So I decided to see what happened if I pulled as many values as possible from my dataset (city name, state, date, metro area, county) and ask the AI for a clear outcome: 2-3 key reasons why the forecast is -0.90%, based on trends specific to the region. By giving the AI as much data to go off of as possible, and stating a clear and desired outcome, I got a much better response:
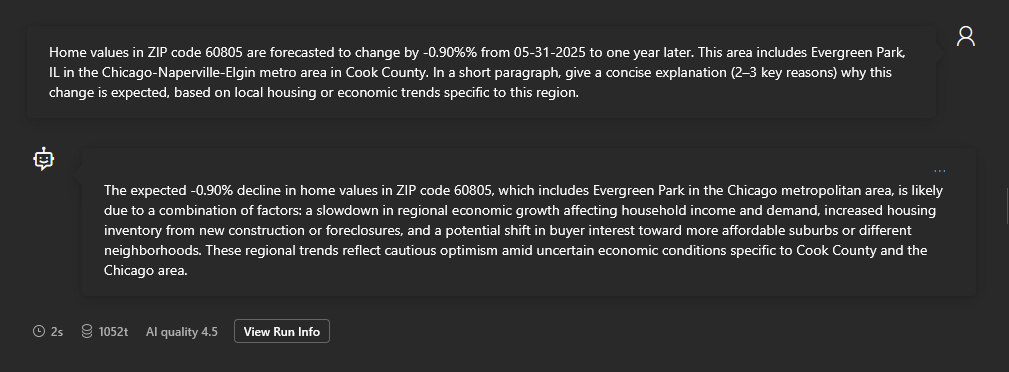 |
|---|
| IMPROVED PROMPT |
The same principles apply to the AI system instructions (shown in the next section).
GPT-4 Engines In-Depth Comparison
I’m going to focus on the GPT-4.1 series as these models seem to be the leaders in general knowledge base and understanding user intent.
- GPT-4.1
- GPT-4.1-mini
- GPT-4.1-nano
To demonstrate the differences in response, I’ve deployed each version and connected them to my Grounding w/ Bing. I’m going to feed each one a prompt that I’m using in my own Zillow Housing Forecast application.
# Instructions
You are a real estate analyst who specializes in regional housing trends.
Your answers are short but highly specific to the ZIP code, city,
and regional context given. Avoid repeating generic causes
like 'interest rates' unless clearly relevant.
# Prompt 1
Home values in ZIP code 06103 are forecasted to change by 3.4% from 05-31-2025 to
one year later. This area includes Hartford, CT within the
Hartford-East Hartford-Middletown, CT metro in Hartford county. In a short paragraph,
give a concise explanation (2–3 key reasons) why this change is expected,
based on local housing or economic trends specific to this region.
# Prompt 2
Home values in ZIP code 29702 are forecasted to change by -5.7% from 05-31-2025 to
one year later. This area includes Blacksburg, SC, within the Gaffney metro area
in Cherokee County. In a short paragraph, give a
concise explanation (2–3 key reasons) why this change is expected, based on local
housing or economic trends specific to this region.
Prompt 1 responses
GPT-4.1: Home values in ZIP code 06103 are projected to rise by 3.4% due to continued revitalization of downtown Hartford, which has attracted new employers and residents, boosting demand for centrally located housing. Additionally, limited new construction and a relatively low housing inventory in the city core are sustaining upward pressure on prices despite broader metro area affordability concerns.
4.1-mini: The 3.4% forecasted increase in home values in ZIP code 06103 reflects sustained demand driven by Hartford’s strong government and healthcare employment base. Additionally, the area’s limited new housing development and tight inventory levels in Hartford county continue to constrain supply, supporting price growth. These localized factors together create upward pressure on home prices over the next year.
4.1-nano: The forecasted 3.4% increase in home values in ZIP code 06103 is driven by steady demand from Connecticut’s government and healthcare sectors, which dominate the local economy. Additionally, limited new housing development and constrained inventory in Hartford support upward pressure on property prices.
Prompt 2 responses
GPT-4.1: Home values in ZIP code 29702 (Blacksburg, SC) are forecasted to decline by -5.7% over the next year, largely due to sluggish local job growth and an increase in housing inventory. The Gaffney metro area has seen several new residential developments, which, combined with slower population growth and limited in-migration, has led to more homes on the market than buyers. Additionally, regional manufacturing layoffs have dampened buyer demand, putting further downward pressure on home prices.
4.1-mini: The expected -5.7% decline in home values in ZIP code 29702 (Blacksburg, SC) is driven primarily by a shift to a buyer’s market, where increased housing inventory and longer days on market indicate weaker demand. Additionally, price declines in larger homes suggest reduced interest in higher-priced segments, while slower economic growth in Cherokee County may also be tempering buyer activity. These local housing supply-demand imbalances and economic factors are key reasons behind the forecasted value drop.
4.1-nano: The -5.7% forecasted decline in home values for ZIP code 29702 is driven by slowing manufacturing activity in Cherokee County and a related decline in local employment opportunities. Additionally, limited population growth and increased housing supply are putting downward pressure on home prices in the Blacksburg area.
Takeaways from the test results
It’s no surprise that the full 4.1 engine offers the best explanations. I particularly like how it mentions the “continued revitalization of downtown Hartford”. I also like that it caught the fact that Gaffney metro area home values are falling off despite seeing several new residential developments. These interesting details weren’t mentioned by the smaller mini and nano engines.
That being said, I think that the mini engine gets 85% of the way there while costing a fifth of the price and having half as long loading times. As for the nano, its responses were too generic for my use case.
Cost Analysis
AI agents are priced per 1 million tokens. 1 token equals roughly 3/4 of a word. My input prompt above uses roughly 100 tokens and the outputs also use about 100.
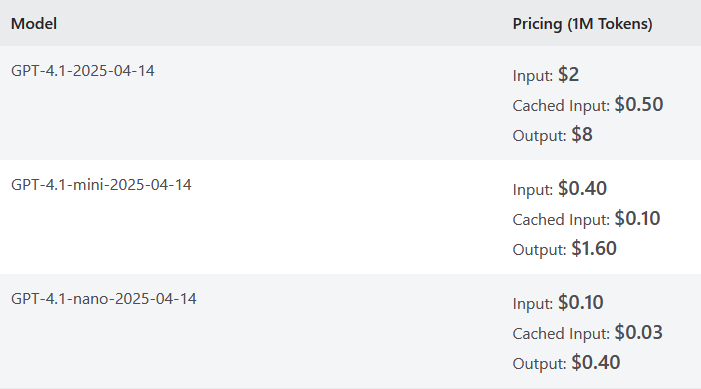
For an avg of 100 input tokens and 100 output tokens, assuming no cache:
Cost Breakdown per 1,000 requests (includes $35 for Grounding)
- GPT-4.1: $36
- GPT-4.1-mini: $35.20
- GPT-4.1-nano: $35.04
Yes you read that right. The AI agent cost is negligible compared to that $35 Grounding tax.
Cost Optimization Strategies (Rate Limiting, Redis Caching, CAPTCHA)
Maybe your public app gains an unexpected amount of traction. Maybe a malicious actor writes a script to spam API calls and rack up some serious bills. Whatever the case may be, it is of utmost importance to implement prevention measures and maintain excellent observability and alerting practices.
Azure Budget alerts
The most important and obvious one. In Azure Portal navigate to Cost Management + Billing > Budgets > Add.
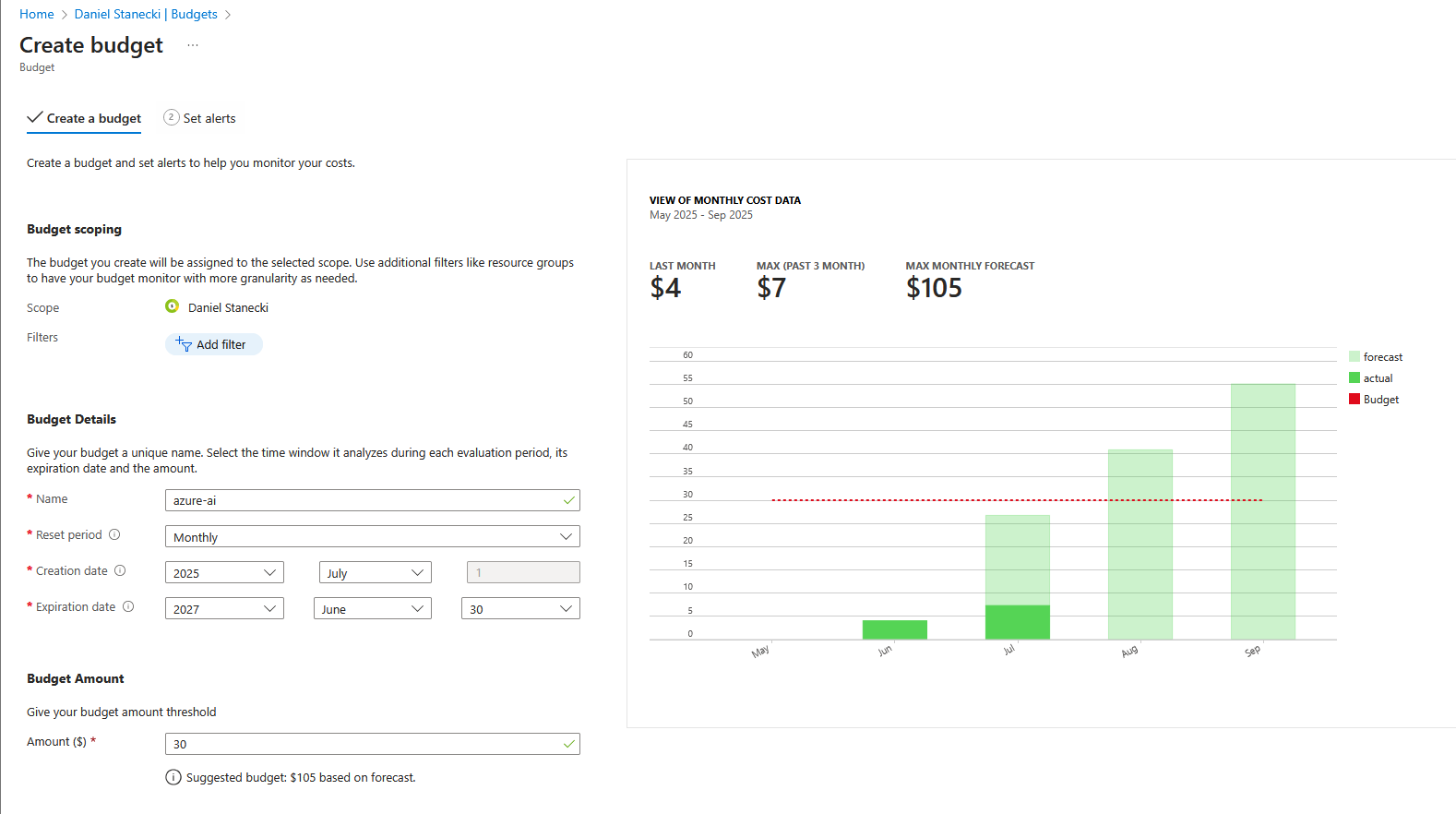
Azure AI token rate limit
I already touched on tokens-per-minute rate limiting earlier (in Azure AI deployment settings) and I’ve set mine to a relatively conservative 2,000 per minute. In my case, each request takes about 100 input tokens and 100 output tokens. So my public app will set a global limit of about 10 requests per minute.
Now, the AI agent cost will be negligible compared to the Grounding cost in this instance. If someone were to spam 10 requests per minute for 12 hours straight (14,400 requests), you would see a bill of over $500. So we’re going to need to implement several more protection measures.
CloudFlare rate limiting
CloudFlare offers DDoS protection free of charge for all domains on Layer 3/4. It does not include Layer 7 rate limiting for free.
Redis cache + Flask-limiter for cluster-wide Layer 7 rate limiting
We can use Redis to both cache AI responses and limit client requests. I’m using Flask session to store data on the client side. For multi-pod apps such as this one, a distributed cache like Redis is required to set a true rate limit.
-
Install Redis Helm chart. My nodes have 4GB each so I specified some arguments to make it more lightweight (the default replicaCount is 3 and each is quite hungry for RAM).
# Dev example, 0 replicas and no monitoring helm install my-redis bitnami/redis -n dev \ --set architecture=standalone \ --set replica.replicaCount=0 \ --set master.persistence.enabled=true \ --set master.persistence.size=256Mi \ --set metrics.enabled=false \ --set redis.extraFlags="{--maxmemory 150mb,--maxmemory-policy allkeys-lru}" # Sets memory limit per pod and allow Redis to eject all keys starting with Least Recently Used # Prod lightweight example, 1 replica helm install my-redis bitnami/redis -n prod \ --set architecture=standalone \ --set replica.replicaCount=1 \ --set master.persistence.enabled=true \ --set master.persistence.size=256Mi \ --set metrics.enabled=true \ --set redis.extraFlags="{--maxmemory 150mb,--maxmemory-policy allkeys-lru}" - In Dockerfile: RUN pip install flask-limiter[redis]
- Redis helm install creates a kubernetes secret for you named “my-redis”, key=redis-password
-
Set up env variables for pods
containers: - env: - name: REDIS_PASSWORD valueFrom: secretKeyRef: name: my-redis key: redis-password - name: REDIS_HOST value: my-redis-master.namespace.svc.cluster.local # replace 'namespace' with yours - name: REDIS_PORT value: "6379" -
Set up Python Code
import redis from flask_limiter import Limiter from flask_limiter.util import get_remote_address REDIS_PASSWORD = os.getenv("REDIS_PASSWORD") REDIS_HOST = os.getenv("REDIS_HOST") REDIS_PORT = os.getenv("REDIS_PORT", "6379") REDIS_URI = f"redis://:{REDIS_PASSWORD}@{REDIS_HOST}:{REDIS_PORT}" # Flask rate limiter (per-client, Layer 7) limiter = Limiter( key_func=get_remote_address, storage_uri=REDIS_URI, app=app, ) # Connect to Redis to cache AI responses redis_client = redis.StrictRedis.from_url(REDIS_URI, decode_responses=True) # In example function: @app.route('/example', methods=['POST']) @limiter.limit("6 per minute") # SET LIMIT PER CLIENT IP def example(): # Set up Redis cache key cache_key = f"explanation:{zip_code}" cached_explanation = redis_client.get(cache_key) if cached_explanation: explanation = cached_explanation else: # Call Azure OpenAI try: response = client.chat.completions.create() explanation = response.choices[0].message.content # Cache explanation for 30 days redis_client.setex(cache_key, 2592000, explanation) except Exception as e: explanation = f"(AI explanation unavailable: {str(e)})" - Test
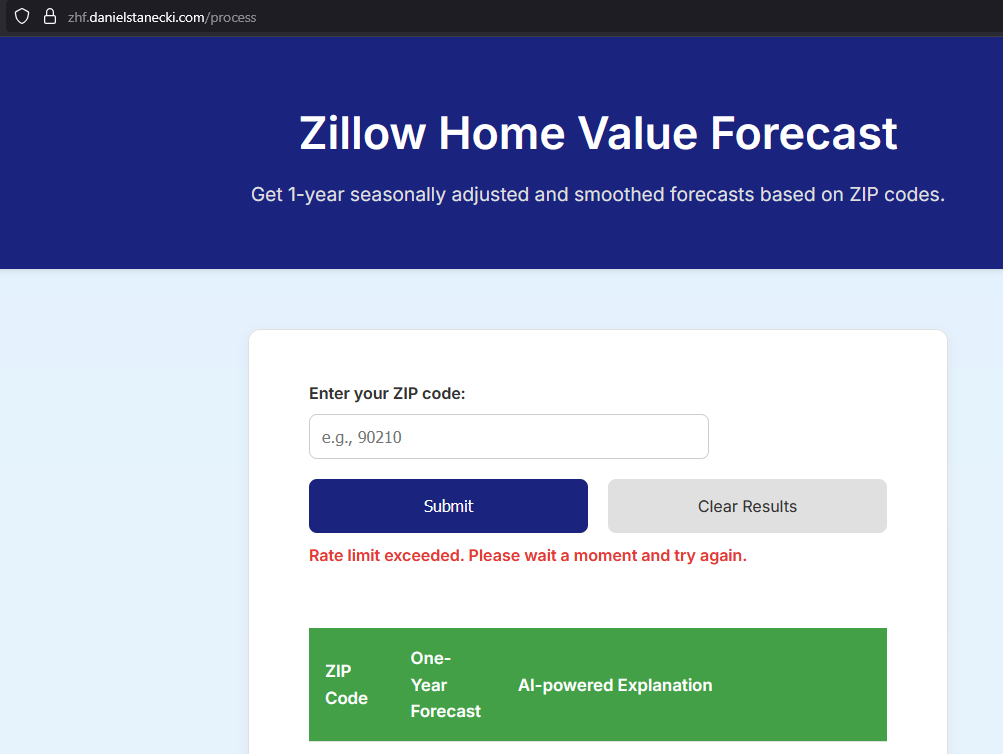
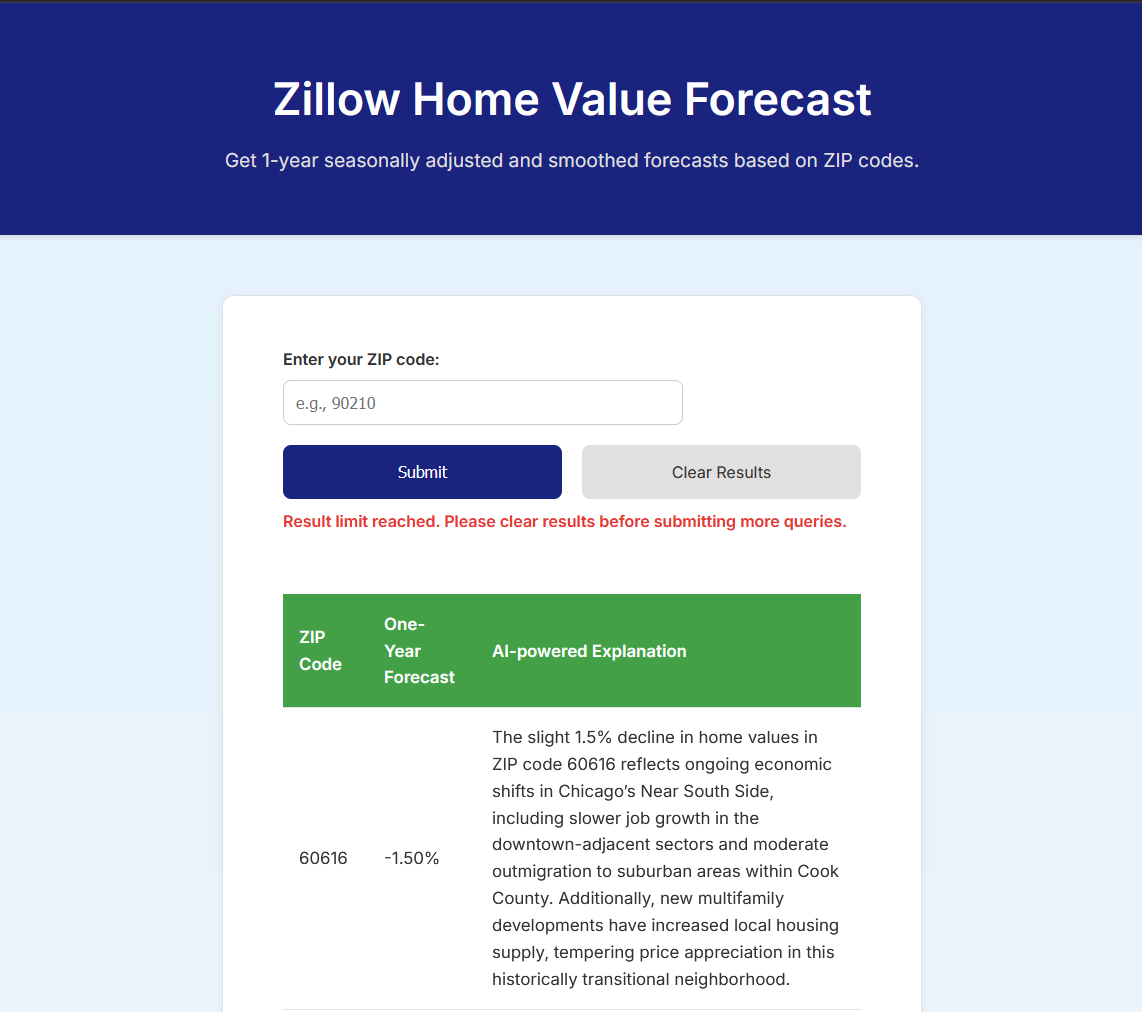
You’ll also notice in my live demo that duplicate ZIP entries load instantly and are identical.
Flask session limit
Another preventative measure I can put in place is a session limit. This means that if users exceed a certain number of results stored on their client side, they will be required to click my “Clear Results” button (delete session and subsequently be required to reCAPTCHA again).
@app.route('/example', methods=['POST'])
@limiter.limit("6 per minute")
def example():
try:
zip_code = request.form['zip']
# Enforce session cap of 10
if 'results' in session and len(session['results']) >= 10:
error = "Result limit reached. Please clear results before submitting more queries."
return render_template("index.html", rows=session['results'], error=error, recaptcha_site_key=RECAPTCHA_SITE_KEY)
Since the session data is stored client-side, it will work across pods without further modification.
Traefik Middleware
Layer 7 rate limiting can be applied using a Kubernetes Middleware object. I talk about that in my blog post: Exposing a K8s App Behind CGNAT on a Multi-Node, Bare Metal Raspberry Pi Cluster
CAPTCHA
Choose between v2 (“I’m not a robot” checkbox) or v3 (score is assigned to user in the background). I’m going to start with v2 and store it in the Flask session so that users don’t have to check the box with every single submission. In the future, I might switch to v3 and have a fallback to v2 if user scores under the v3 threshold.
v2 steps:
- Visit https://www.google.com/recaptcha/admin and create a reCAPTCHA for your domain. Copy down the site key and secret key
- Create a kubernetes secret for the secret key which will be passed to Flask as an env variable
-
Add the Python code
# reCAPTCHA RECAPTCHA_SECRET_KEY = os.getenv("RECAPTCHA_SECRET_KEY") RECAPTCHA_SITE_KEY = os.getenv("RECAPTCHA_SITE_KEY") def verify_recaptcha(token): payload = { 'secret': RECAPTCHA_SECRET_KEY, 'response': token } try: r = requests.post("https://www.google.com/recaptcha/api/siteverify", data=payload) return r.json().get("success", False) except: return False @app.route('/process', methods=['GET', 'POST']) def process(): try: zip_code = request.form['zip'] # First-time users must solve reCAPTCHA if not session.get('captcha_passed'): token = request.form.get('g-recaptcha-response') if not verify_recaptcha(token): error = "reCAPTCHA verification failed. Please try again." return render_template("index.html", rows=session.get('results', []), error=error, recaptcha_site_key=RECAPTCHA_SITE_KEY) session.permanent = False # expires on browser close session['captcha_passed'] = True